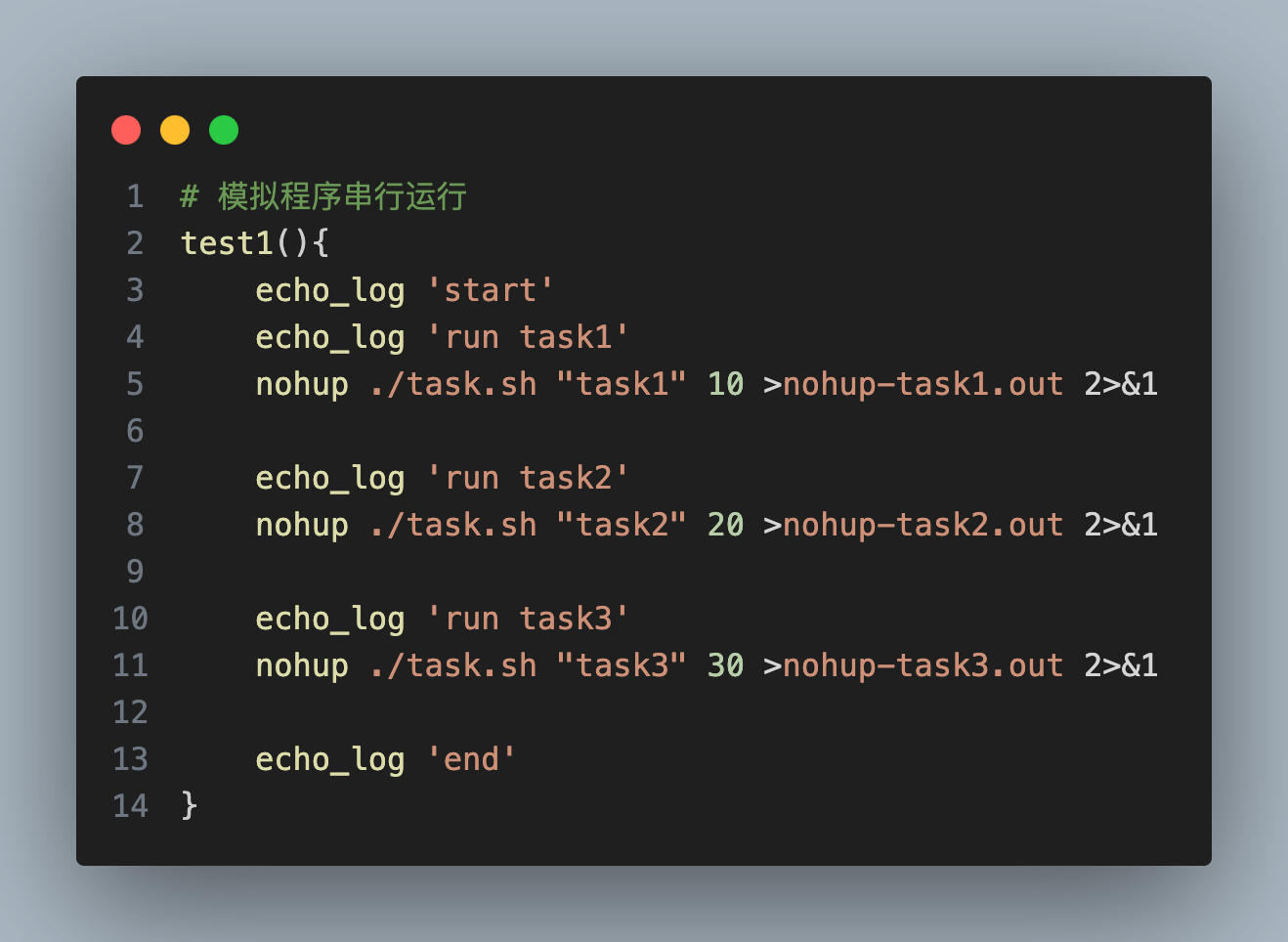
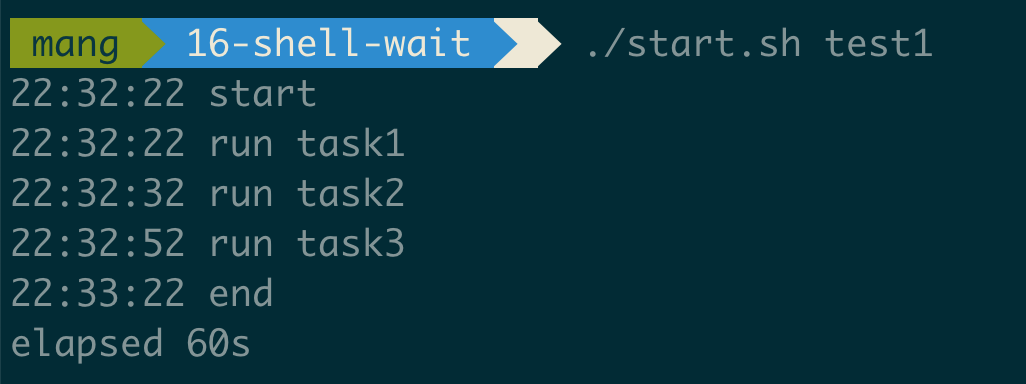
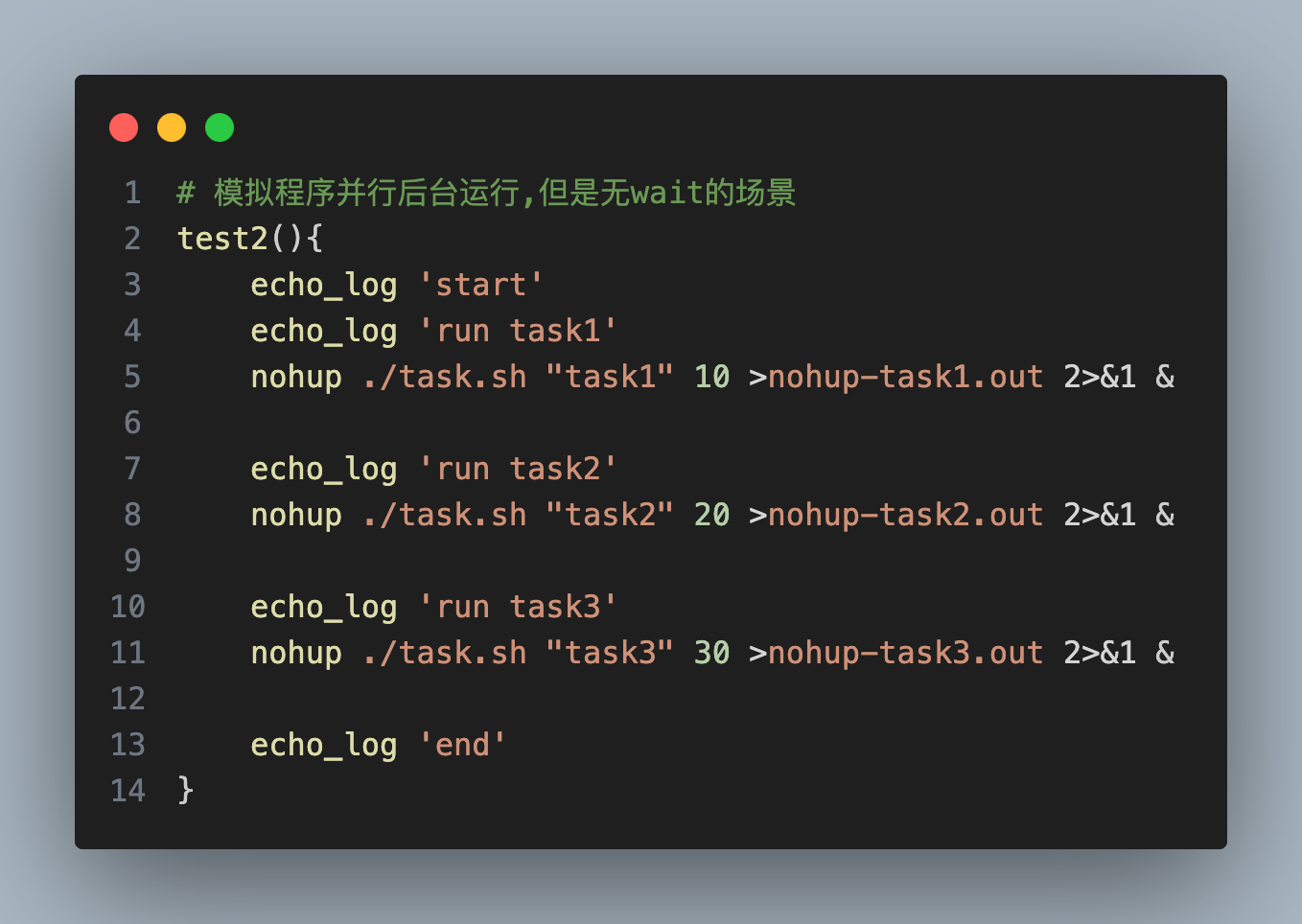
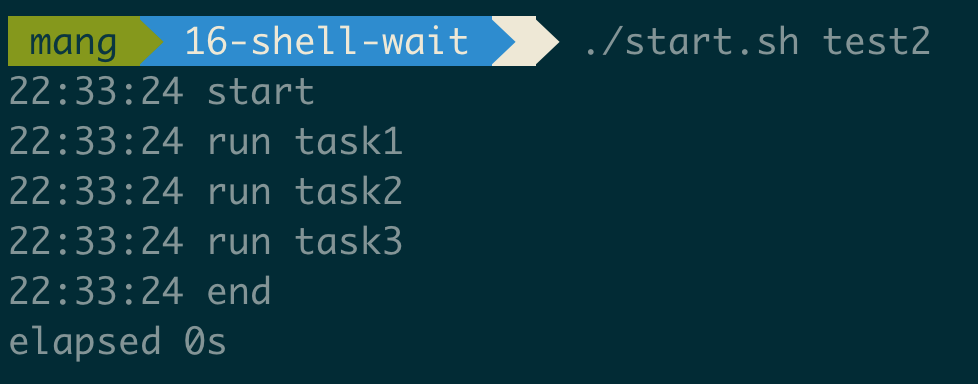
背景说明 如果你的工程中使用maven, 你是否亲自处理过jar包冲突 ?
jar包冲突一般是间接依赖引起的,举个例子,假如你在项目中使用了2个jar包,分别是A和B, 现在A依赖C, B也依赖C, 但是A依赖的C的版本是1.0, B依赖的C的版本是2.0。
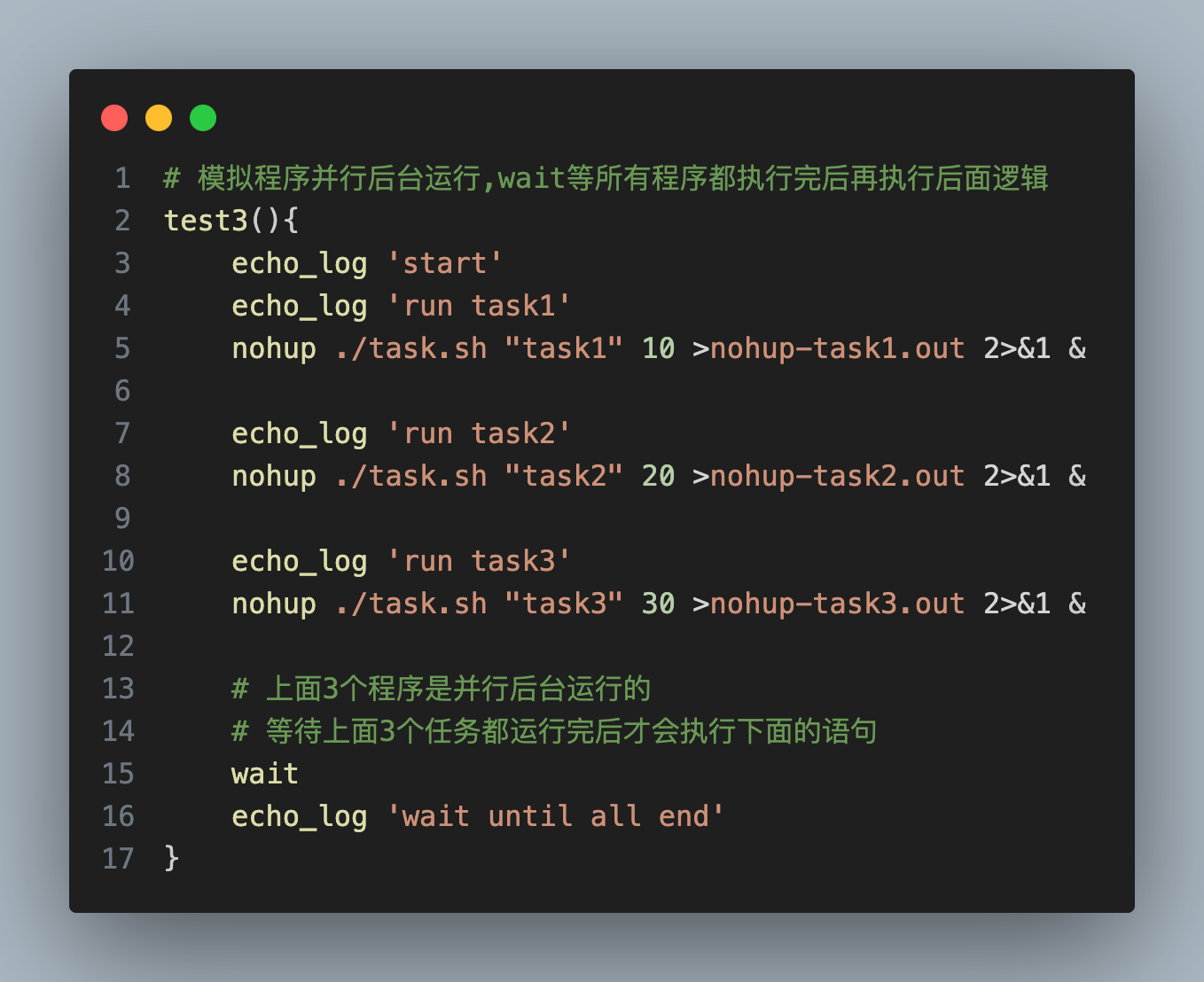
这时候你的项目中的C就会有2个不同的版本,这时maven会依据自己的原则,来决定使用哪个版本的jar包, 而另一个无用的的jar包则未被使用,这就是所谓的依赖冲突 。
在大多数情况下,依赖冲突并不会对系统造成什么异常,但是在某些情况下,有可能会出现找不到类的异常, 因此理解冲突导致的原因并且快速定位到冲突源,是每个程序员的必修课 。
这里列出一些常见的由于jar包冲突导致的异常
程序抛出java.lang.ClassNotFoundException异常
程序抛出java.lang.NoSuchMethodError异常
程序抛出java.lang.NoClassDefFoundError异常
程序抛出java.lang.LinkageError异常等
这些是能够直观呈现的,当然还有隐性的异常,比如程序执行结果与预期不符等。
原理介绍 上面介绍了什么是jar包冲突以及jar包冲突有可能产生的错误, 本节讲一些maven jar包管理原则,了解这些背景知识会帮助我们解决jar包冲突。
依赖传递 当在maven项目中引入A依赖,A依赖通常又会引入B的jar包,B可能还会引入C的jar包。这样,当你在pom.xml文件中添加了A依赖,maven会自动帮你把所有相关的依赖都添加进来. 这就叫做依赖传递 . transitive dependencies
maven引入依赖传递机制,一方面大大简化和方便了依赖声明,另一方面,大部分情况下我们只需要关心项目的直接依赖是什么,而不用考虑这些间接依赖 。但有时候,当依赖传递造成问题的时候,我们就需要清楚地知道该传递性依赖是从哪条依赖路径引入的。
依赖调解 上一节讲了maven的依赖传递, 其是jar包冲突产生的原因, 而当maven中出现依赖冲突时,其又是如何解决的呢? 这就涉及到依赖调解,maven中有2条处理依赖的原则
第一原则:最短路径优先原则
第二原则:最先声明优先原则
最短路径优先原则
主要根据依赖的路径长短来决定引入哪个依赖 (两个冲突的依赖)
示例:
项目中同时引入了A和B两个依赖,它们都间接引入了Z依赖,但由于B的依赖链路比较短,因此最终生效的是Z(20.0)版本。这就是最短路径优先原则。
此时如果Z的21.0版本和20.0版本区别较大,那么就会发生jar包冲突的表现
最先声明优先原则
如果两个依赖的路径一样,最短路径优先原则是无法进行判断的,此时需要使用最先声明优先原则 ,也就是说,谁的声明在前则优先选择谁。
示例:
A和B最终都依赖Z,此时A的声明(pom中引入的顺序)优先于B,则针对冲突的Z会优先引入Z(21.0)。
如果Z(21.0)向下兼容Z(20.0),则不会出现Jar包冲突问题。但如果将B声明放前面,则有可能会发生Jar包冲突
工程问题总结 上面说的都是原理,可能大家更关心的是如下2个问题
我的项目中到底有没有依赖冲突? 冲突是从哪里引入的?
解决思路 方法1 maven-dependency-plugin 插件 maven-dependency-plugin插件可以打印依赖树,如果加上-Dverbose参数可以查看更详细的日志,当然也包括冲突的jar包
1 mvn dependency:tree -Dverbose
但是很少有人告诉你该插件从3.0开始不再支持 -Dverbose 参数 ,所以即使加上该参数其也不会输出冲突的jar包,如果使用该参数会看到如下的日志
1 Verbose not supported since maven-dependency-plugin 3.0
所以正确的命令是指定一个支持-Dverbose参数的版本,例如2.10版本
1 mvn org.apache.maven.plugins:maven-dependency-plugin:2.10:tree -Dverbose > tree.txt
方法2 IDEA 插件 Maven Helper 在这里向大家推荐IDEA 解决Maven依赖冲突的高能神器 Maven Helper。
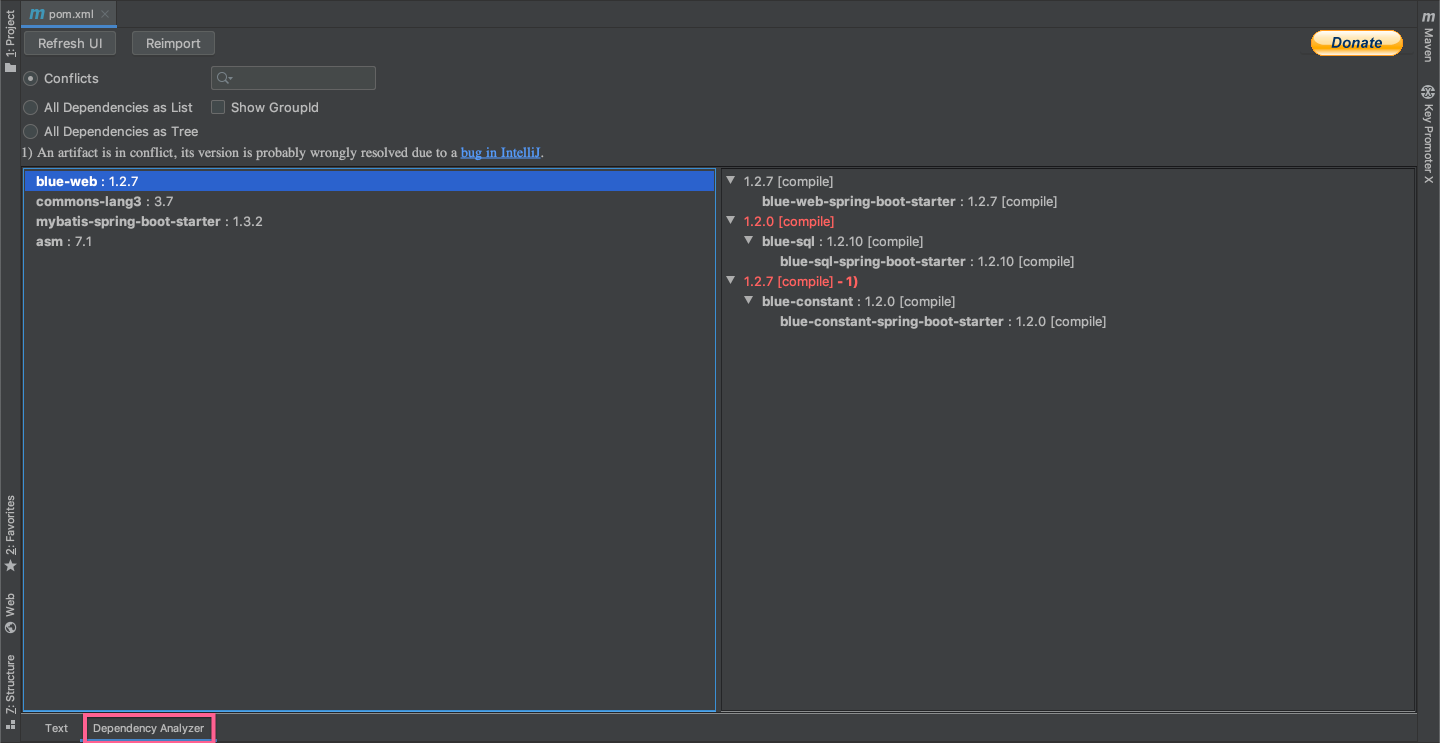
当你安装完该插件后,打开pom.xml 会看到一个 Dependency Analyzer 的标签页
其有三大功能,而且还提供搜索功能方便使用
Conflicts(查看冲突):可以很方便的看出哪些jar包冲突,其冲突是从哪些jar包引入的, 最终用的是哪个版本
All Dependencies as List(列表形式查看所有依赖)
All Dependencies as Tree(树形式查看所有依赖)
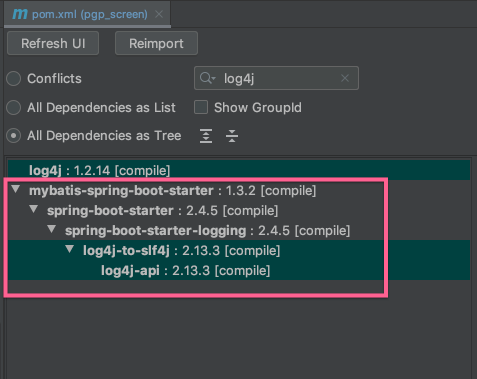
实践案例 案例1 log4j漏洞爆发后快速定位log4j-2.X的引入源头 2021年12月7日 log4j爆发了史诗级漏洞,log4j这个再平常不过的jar包,如今却变成了洪水猛兽,只要工程中有log4j-2.X相关版本的jar包,都要立即清除,当时需要确认工程中是否引入了log4j-2.X版本, 我们确实没有在工程中显式引入log4j-2.X,但是最终的lib中确实有log4j-2.X相关的jar包。
我们希望能快速定位到是哪个依赖间接引入了log4j-2.X, 当时就借助了Maven Helper插件,很快定位到问题。
如下可以看到是mybatis-spring-boot-starter这个依赖间接引入了log4j-2.X 相关的jar包
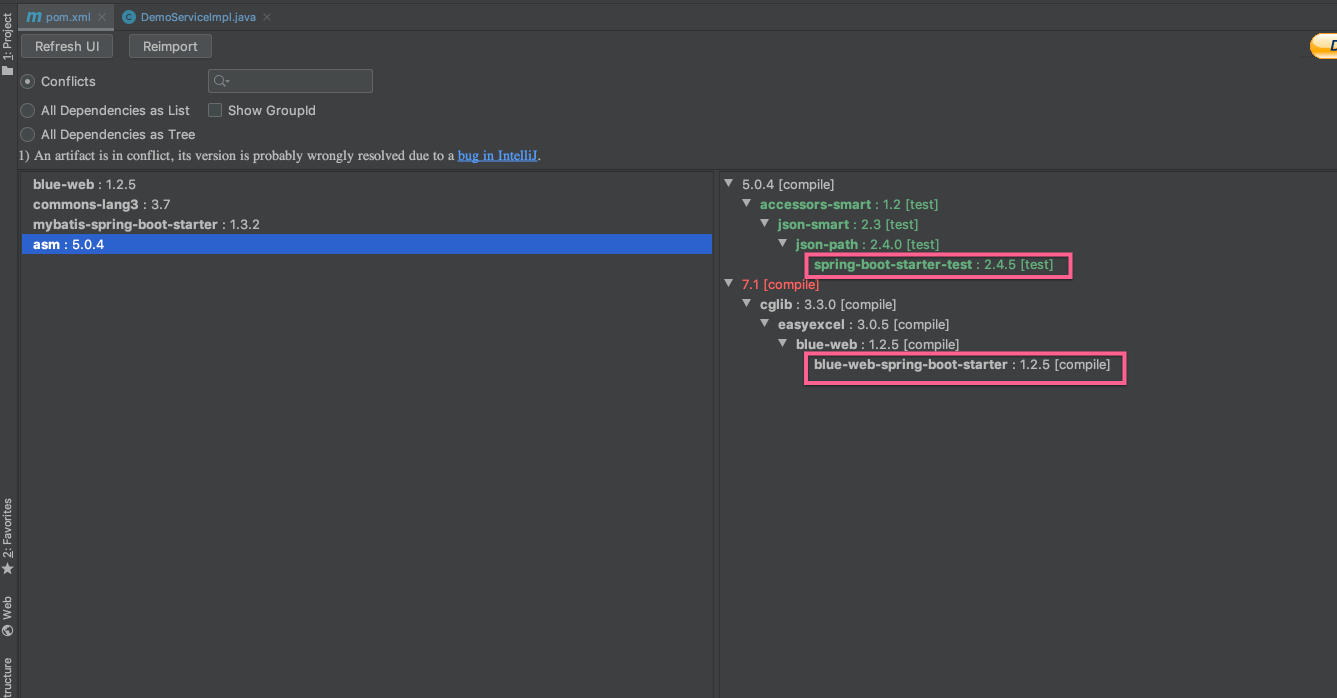
案例2: 引入 EasyExcel 引发 asm依赖冲突 项目中有excel导出功能,所以引入了EasyExcel, 当时希望将导出excel的功能封装到一个jar包里,但是在使用的过程中有报错,后来定位到问题与依赖冲突有关系。
当时就借助Maven Helper插件, 可以看到spring-boot-starter-test 依赖asm 5.0.3, blue-web中通过easyexcel依赖asm 7.1, 而最终使用的asm的版本是通过spring-boot-starter-test 引入的, 定位到冲突的产生的根源后,我们很快解决了问题。
结语 理解冲突导致的原因并且快速定位到冲突源,是每个程序员的必修课,希望通过该文档的讲解能帮助到大家。
微信端的朋友也可关注我的公众号
小马向前走