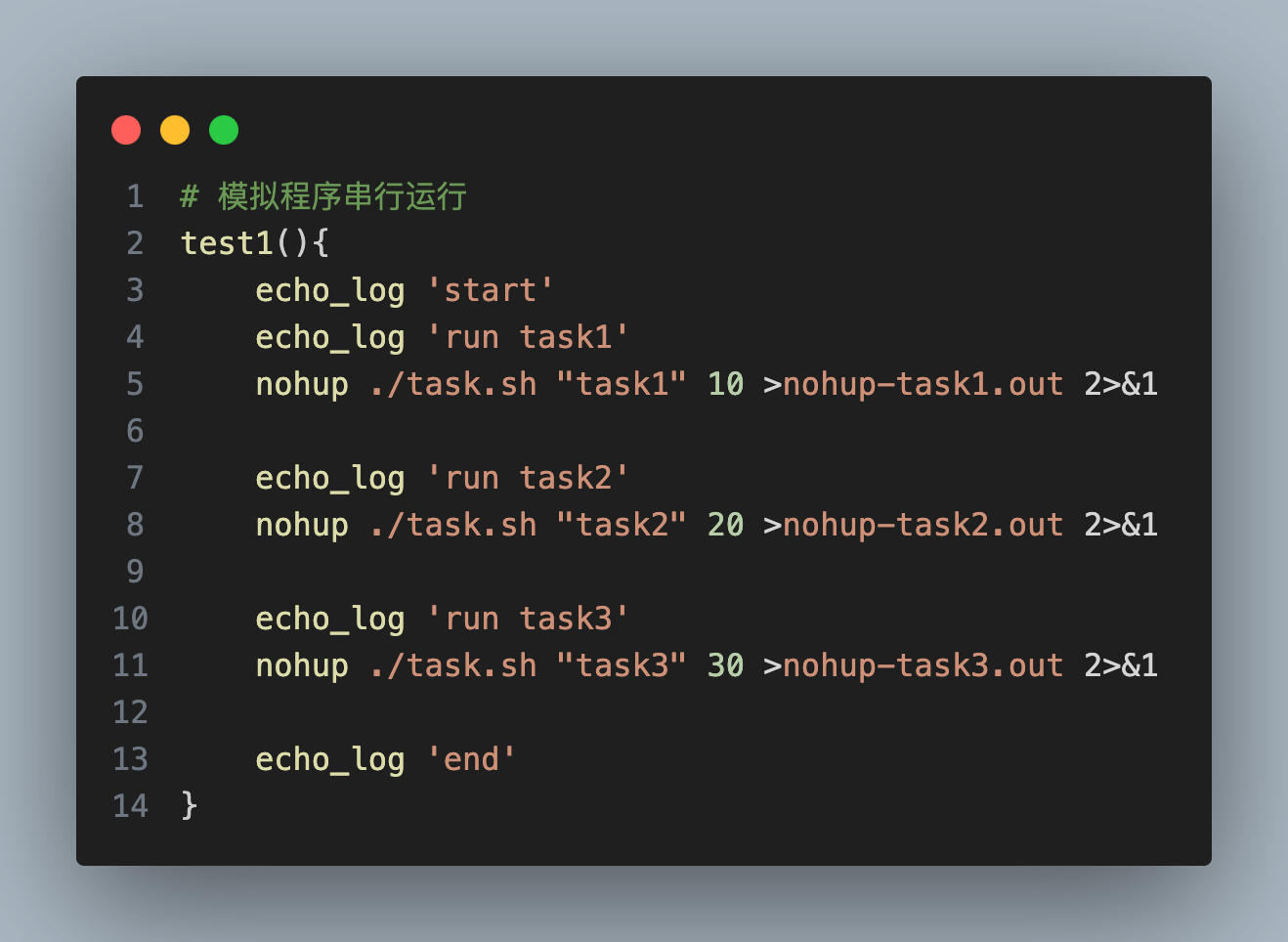
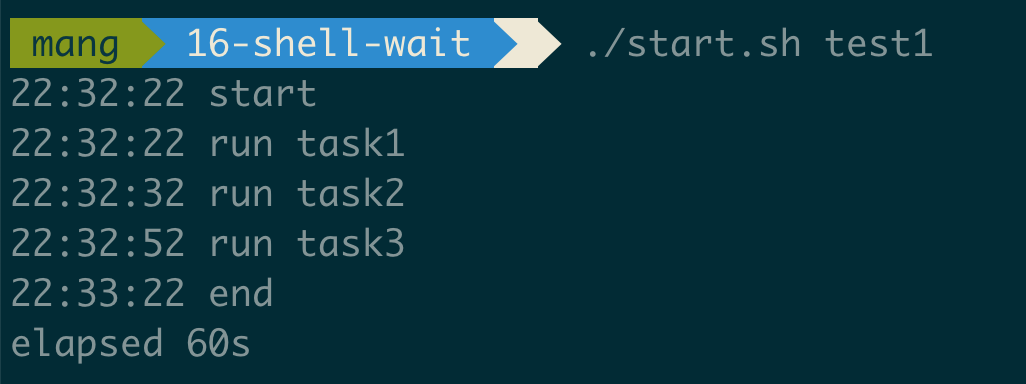
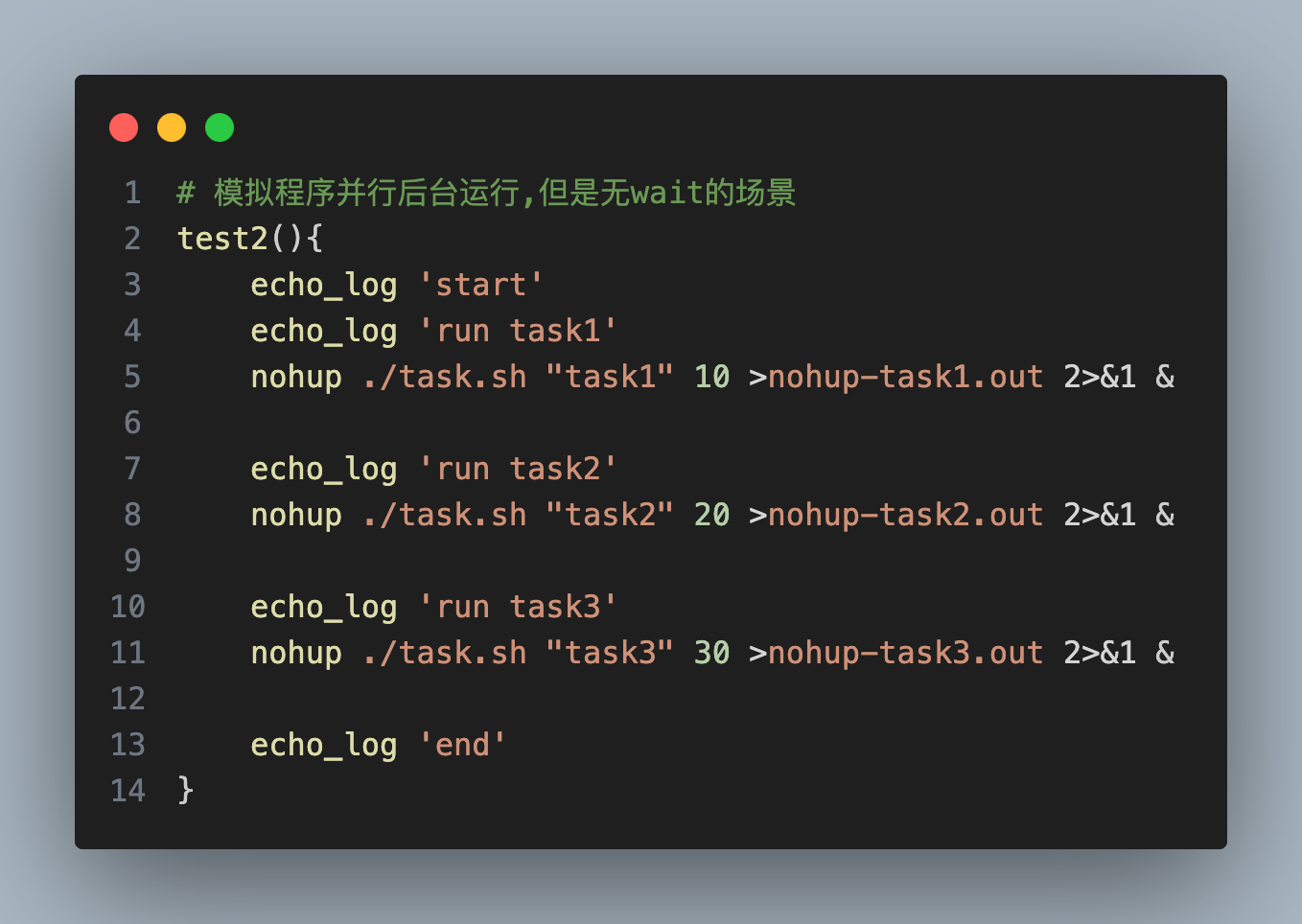
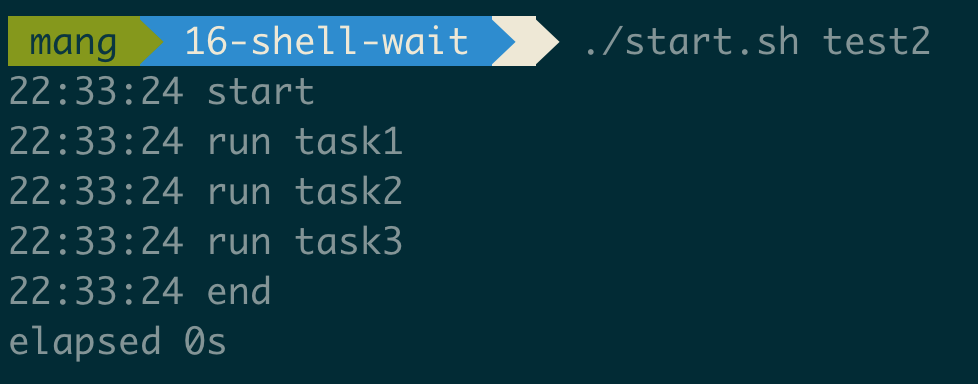
引言
深度使用 Cursor 有一段时间了,老实说,一开始我对所谓「AI 颠覆编程」的论调是带有几分警惕的,但当它实实在在地帮我完成了几次繁琐的代码重构后,我发现了一件令我头皮发麻的事:
它不仅理解我代码语义层面的逻辑,它甚至洞悉了我为什么这么设计。
那一刻,我突然有种高山流水遇知音的感觉:有了这样一个懂我的神器,我离传说中的 10 倍程序员,真的只差一个 Cursor 么?

实战派:它是如何融入我日常工作流的?
经过这段时间的磨合,Cursor 已经渗透到了我的日常开发中,成为了名副其实的提效利器。真正让它封神的,绝不是常规的一问一答式聊天,而是它对代码上下文的深度介入。 接下来,我结合几个高频实战场景,给大家分享一些常规对话之外的深度使用技巧。
局部手术刀:内联聊天 (CMD + K)
这个功能极其适合处理局部代码的“疑难杂症”。选中一段代码,按下 CMD + K,就能直接对这段代码下达指令。我最近高频使用的场景包括:
- 骨架填充:我非常看重对代码主导权的把控。面对复杂的代码逻辑,我习惯先用伪代码搭好核心“骨架”,再让 Cursor 去填充实现细节。这种“我定方向,AI执行”的模式,让我在享受极速编码的同时,又始终牢牢把控着代码的架构与灵魂。因为我深知:初级使用者被 AI 牵着走,而资深开发者始终把控着代码的架构和灵魂。
- 精准“微创”修改:很多时候我只需要调整某几段逻辑,最怕AI“自作聪明”把整个文件全改一遍。通过选中特定代码块下发指令,它就只在划定的范围内“指哪打哪”,绝不误伤其他无辜代码。
- 自动补全注释:选中那些“当年只顾着爽,忘了写注释”的工具函数,一键生成清晰的说明。
- 代码瘦身:把几个过于冗长、复杂度极高的函数扔给它,它总能给出极其优雅的重构方案。
- 边界防御:写完一段核心逻辑后,让它帮忙检查是否有遗漏的边界情况和异常处理。
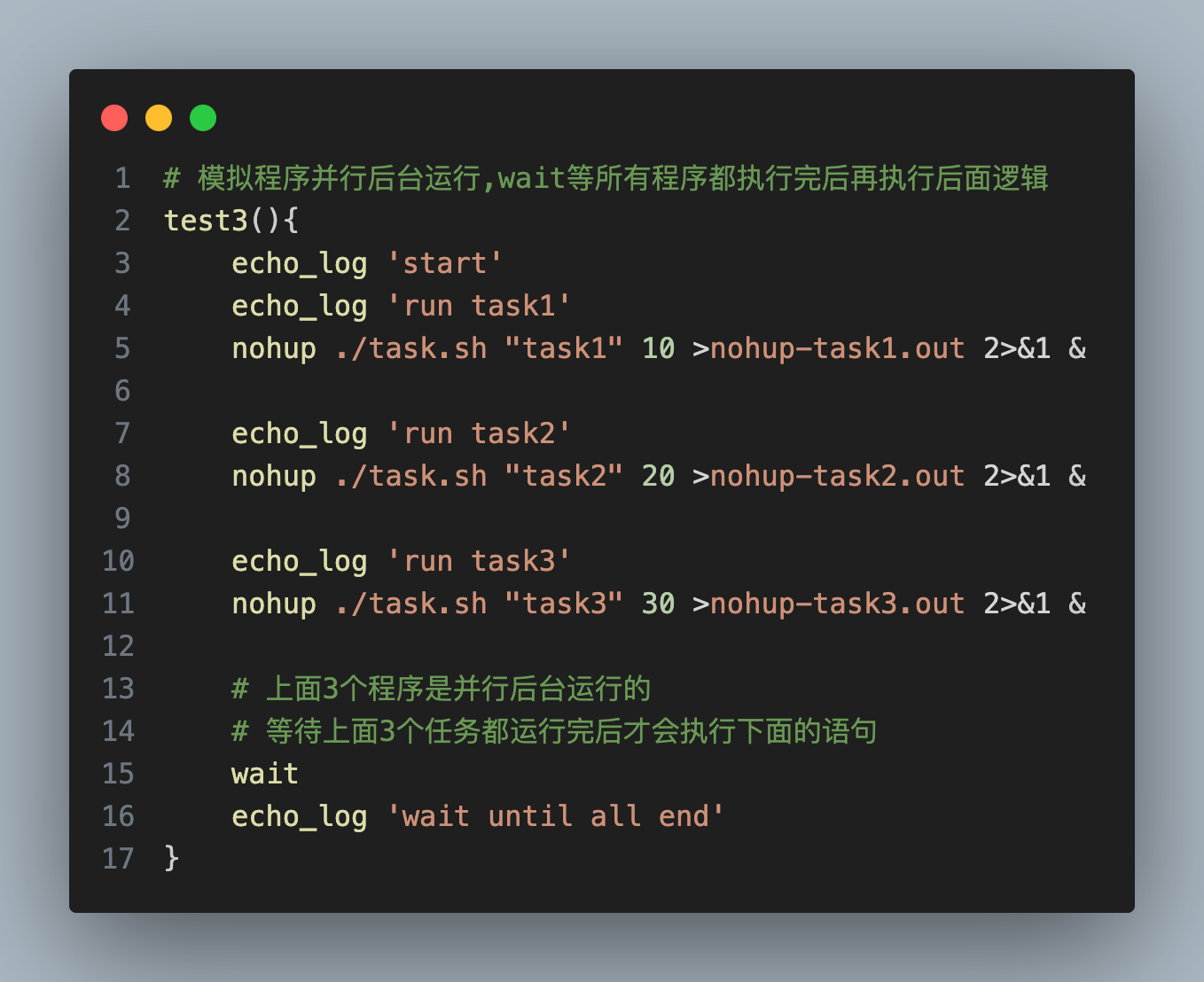
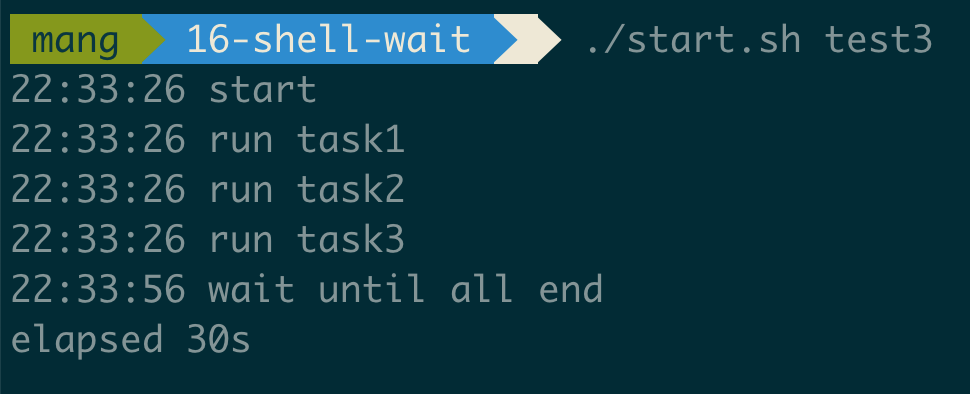
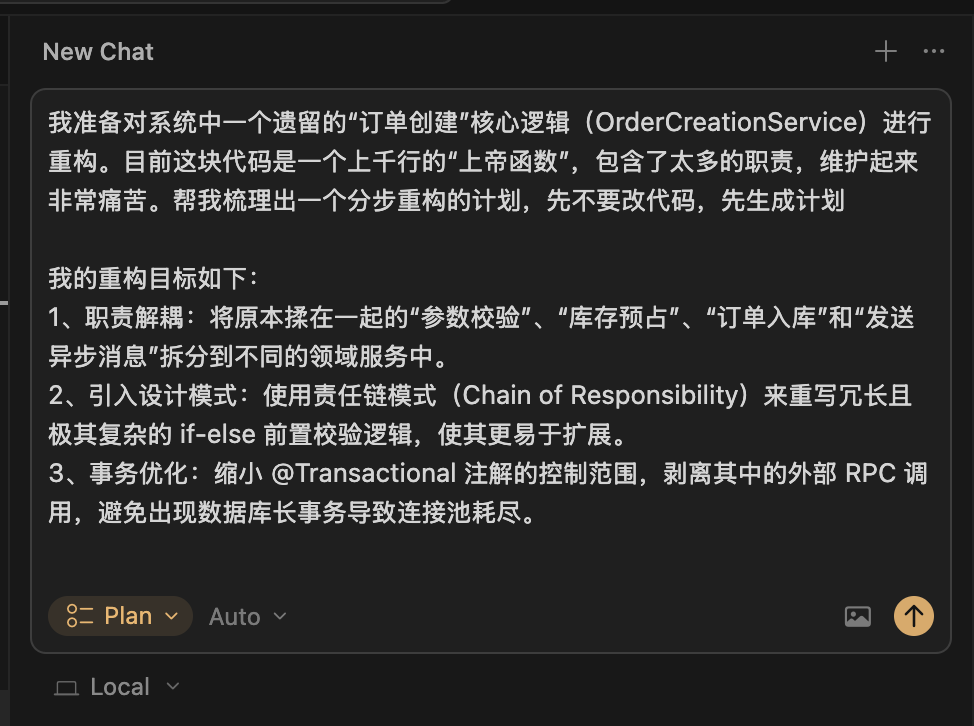
谋定而后动:计划功能 (Plan)
在做稍微复杂的模块改造前,我会先用它的“计划功能”。反复和 AI 沟通改造的步骤,这不仅是让AI清楚我的意图,更是一个帮我自己理清思路的过程。思路清晰了,写代码不过是顺水推舟。
双剑合璧:IDEA 与 Cursor 的无缝切换
虽然 Cursor 很强,但作为一个重度依赖 IntelliJ IDEA 的开发者,我深知 IDEA 在项目工程化管理、复杂重构以及对开发工具链的深度集成方面,依然具有不可替代性。我无法、也不想完全脱离 IDEA。
如何让这两者共存?我找到了两个堪称神器的插件,完美打通了我的工作流:
1. Switch2Cursor (IDEA 插件) 在 IDEA 中安装后,只需一个快捷键,就能瞬间在 Cursor 中打开当前正在开发的项目或特定文件。遇到需要 AI 强力介入的代码,一键穿梭过去。
![]()
如下是快捷键

2. Switch2IDEA (Cursor 插件) 同理,在 Cursor 中利用 AI 快速生成、修改完代码后,利用此插件可以立刻切回 IDEA,继续享受熟悉的编译和调试环境。
![]()
借助这两个插件,Cursor 已经成为我在 IDEA 旁边不可或缺的“最强外挂“。
守卫控制权:与 Git 的天作之合
AI 写代码速度虽快,但我绝不会让它脱离掌控。为了防止AI“夹带私货”或产生意料之外的修改,Git 成了我最重要的一道防线。 每次 Cursor 替我大面积生成或重构代码后,我都会习惯性地利用 Git 快速识别出它到底动了哪些文件、改了哪几行逻辑。这种基于代码 Diff 的审视,本质上就是我跟 AI 之间的一场 Code Review。
边界拓宽者
这些年微服务的兴起,让前后端的分工越来越明确,作为一名擅长跟服务器和数据库打交道的后端开发,以往面对非后端领域的实现细节时,总免不了有些底气不足。但 Cursor 出色的跨语言理解能力,给了我跨越边界的底气。AI 帮我拆掉了不同技术栈之间的那堵墙,让我偶尔也能顺畅地客串一把“全栈工程师”。
杂活终结者:告别“体力活”
渐渐地,我开始把那些看似简单但极度消耗精力的小活全部外包给它:
- 环境与命令:帮我快速生成繁杂的终端操作命令。
- 质量保证:生成完善的单元测试用例。
- 快速上手:面对一个庞大的老工程,用它帮我快速定位代码片段,解释我不熟悉的祖传代码。
- 文字校验:校验技术博客的标点、错别字。
灵魂拷问:我是进化了,还是被驯化了?
Cursor 确实好用,但有时又觉得它好像一点点把我“干废了”。
看着屏幕上一行行由 AI 飞速生成的优雅代码,我的确感受到了效率的狂飙。但静下心来,一种隐隐的担忧随之而来:我好像得到了一些,又好像失去了很多。我究竟是在进化,还是在被逐渐驯化?
当一个 AI 模型能以专家级的水平、极低的成本处理掉 70% 的知识型和体力型编码工作时,我们必须要重新审视一个问题:在 AI 时代,程序员不可替代的核心竞争力到底是什么?
如果敲击键盘写下 for 循环不再是门槛,那么审查代码(Code Review)和掌控全局架构的能力,就成了关键。当代码并非由你亲手敲下时,你需要极其敏锐的嗅觉,才能在一大片看似完美的 AI 代码中,捕捉到隐藏在代码深处的致命 Bug。
结语
回到文章开头的那个问题:我离 10 倍程序员真的只差一个 Cursor 么?
我的答案是:Cursor 可以给你提供 10 倍的产出速度,但如果你没有驾驭和审查这些产出的能力,它也可以给你带来 10 倍的 Bug。
AI 可以帮你干活,可以为你提供无数种方案,但它永远无法替你做决定。你依然要依靠自己的专业认知去拍板,依然要为最终合并到主分支的代码负全责。
五年前,我们需要能看懂代码;五年后,面对汹涌而来的大模型,这个要求依然没变,甚至要求更高了。
大浪淘沙,工具永远在变,但技术人的内核不该变。
微信端的朋友也可关注我的公众号